NAssist
This time I would like to publish my application that I wrote some time ago and I’ve been actively using. I call it NAssist. Purpose of this application is to provide an on demand window (accessed with global keyboard shortcut) that allows to enter some commands whose effects would be displayed inside it.
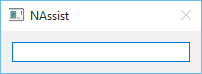
Basic application window
Application is written in Python 3 with PyQt5 and PyWin (for Windows) or python-xlib (for Linux). PyQt is used as an application framework while PyWin or python-xlib are needed for handling global hotkeys.
Usage
Global hotkeys are used to call application which is normally hidden in the background with icon in Notification Area or Tray (both on Windows and Linux). Application window can be called with predefined global hotkeys – CTRL + SHIFT + SPACE. On the other hand the window can be hidden with ESCAPE hotkey while focused.
Application in default mode appears only with one Command field which should be already focused by previously pressing mentioned hotkey combination (CTRL + SHIFT + SPACE). If it’s not, it can be made so by pressing them again. In this state application is ready to accept commands which are defined in __init__ function in mainwindow.py file. Those commands come from modules package.
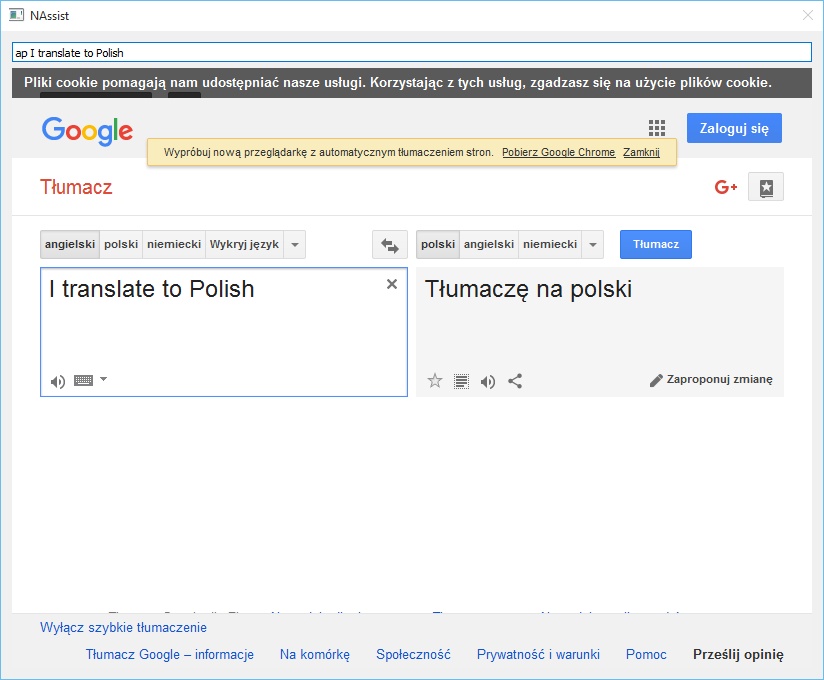
Example of translation from English to Polish
Basic commands that come with the application are:
- ap {text} – English -> Polish translator (google translate),
- pa {text} – Polish -> English translator (google translate),
- np {text} – German -> Polish translator (google translate),
- pn {text} – Polish -> German translator (google translate),
- sjp {word} – Polish language dictionary (sjp.pl).
To use one of those commands simply write them in Command field with arguments after space. The result of “ap I translate to Polish” is presented in the image on the right. As shown, the result appears right below the Command field, also the window is enlarged to make the result visible.
To quickly delete everything from Command field there is an additional hotkey – SHIFT + DELETE.
Writing own modules
Writing own modules is pretty straightforward. It requires a module to handle following events which are defined in BaseModule.py file:
- onKeyPress(event) – key has been pressed inside application window, event represents PyQt event,
- onTextUpdate(text) – argument text has been updated for given module (from command “ap text” only “text” will be passed,
- onActivate() – current module has been activated,
- onDeactivate() – current module has been deactivated (new module will be activated if command was changed, not removed),
- onClose() – application is closing.
The basic commands are implemented using some more specialized base classes that are available for extension:
- TranslatorModule – uses google translator to provide web page with results via “https://translate.google.com/#{}/{}/{}” pattern,
- WebModule – is used to implement above module, can be used to add other webpages as commands.
Download and requirements
Application is already public on GitHub with GPL2 license.
Requirements for Windows:
Requirements for Linux:
- Python 3
- PyQt5 matching Python version
- python3-xlib (pip install python3-xlib)

